
В этом месяце академический мир был потрясен событием мирового масштаба: выяснилось, что очень известная женщина-ученый подделала данные в нескольких своих статьях.
Большой скандал в научном мире прямо сейчас
Речь идет о Франческе Джино, профессоре Гарвардской школы бизнеса – одной из топовых и наиболее престижных школ бизнеса. Сама Джино имеет звание одного из 40 лучших профессоров бизнеса в возрасте до 40 лет и одного из 50 самых влиятельных мыслителей в области управления в мире. Ее академические показатели также очень высоки: например, индекс Хирша равен 87, и это ОЧЕНЬ много.
Что же произошло?
Группа исследователей Uri Simonsohn, Leif Nelson и Joe Simmons из Data Colada выпустила собственное расследование в 4 частях, из которых на сегодня вышло 3. Чтобы не перегружать пост, расскажу только про первую часть. Здесь и далее будет мой вольный пересказ их расследования, все картинки также будут оттуда.
Поехали.
Часть 1. Data Falsificada: "Clusterfake"
Название – отдельный лол, потому что это явно отсылка к слову «clusteruck» – бардак, пиздец, жопа и т.д.
Суть: два соавтора независимо подделали данные для двух разных исследований в статье о нечестном поведении.
Речь идет о статье, уже отозванной за фальсификацию данных в одном из приведенных в ней исследований. Теперь же выясняется, что данные были фальсифицированы еще в одном исследовании, причем независимо. Кстати, одним из соавторов и куратором статьи является другой известный ученый – Дэн Ариели, но сейчас речь не о нем.
Три исследования в этой статье якобы показывают, что люди с меньшей вероятностью будут обманывать, если подпишут обязательство отвечать честно в верхней части бланка согласия, а не в нижней.
Джино была единственным автором, участвовавшим в сборе и анализе данных, о которых пойдет речь.
Суть исследования была вот в чем. Участникам выдавался лист с 20 математическими головоломками, и за решение каждой из них они могли получить по 1 доллару. По прошествии 5 минут участников попросили сообщить экспериментатору, сколько головоломок они решили правильно, и затем выбросить свой лист с ответами. На деле участников вводили в заблуждение, что они могут без палева соврать, потому что каждый лист имел уникальный идентификатор. Таким образом, участники могли жульничать (и зарабатывать больше денег), думая, что никто не узнает, а исследователи могли вычислить, насколько сжульничал каждый участник.
Затем участники заполняли «налоговую» форму, в которой сообщали, сколько денег они заработали, а также сколько времени и денег они потратили, чтобы добраться до лаборатории – экспериментаторы частично компенсировали и эти затраты.
Гипотеза исследования была в том, влияет ли расположение подписи о декларации честности вверху или внизу формы (до или после заявленных расходов и числа решенных задач) на последующее поведение.

В итоге ученые показали очень сильный эффект: подпись сверху, по сравнению с подписью снизу, была связана с куда меньшей долей людей, завысивших свой результат, – соответственно 79 и 37%, а среднее число якобы решенных задач сверх реального было 0,77, по сравнению с 3,94. Ровно так же почти вдвое меньше была средняя сумма заявленных расходов на поездку до лаборатории (с 9,62 до 5,27 доллара).
Впечатляет, правда?
Но
Data Colada обнаружили серьезную аномалию в размещенных на открытом портале данных (привет, open science). В практически идеально отсортированных данных вдруг появляется 8 значений, которых там явно быть не должно:
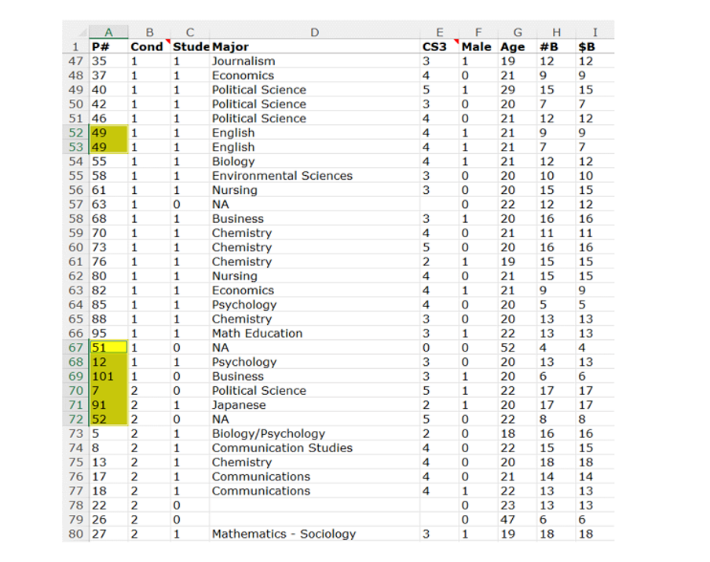
Продублированная запись участника №49 – это меньшая из проблем. Способа отсортировать данные таким образом, насколько известно, нет. Это означает, что выделенные строки либо перемещались вручную, либо менялся номер участника. И, судя по всему, верно первое.
Разумеется, подозрительные строки показывают огромный эффект. Все они являются одними из самых экстремальных наблюдений в своем условии, и все они в предсказанном направлении.

Коварный Excel
Данные для исследования были также опубликованы в виде файла Excel (.xlsx), который содержит формулы. С точки зрения «судебной экспертизы» данных это чрезвычайно ценно.
Малоизвестный факт о файлах Excel заключается в том, что они представляют собой буквально zip-файлы, пакеты файлов меньшего размера, которые Excel объединяет для создания единой электронной таблицы. Например, один файл в этом пакете содержит все числовые значения, которые появляются в электронной таблице, другой содержит все записи символов, третий — информацию о форматировании (например, шрифт Calibri или Cambria) и т.д.
Наиболее важным является файл с именем calcChain.xml. CalcChain сообщает Excel, в каком порядке выполнять вычисления в электронной таблице, примерно так: «Сначала решите формулу в ячейке A1, затем в ячейке A2, затем в B1 и т. д.». CalcChain — это сокращение от «цепочка вычислений».
CalcChain очень полезен в данном случае, потому что он может сообщить, была ли перемещена ячейка (или строка), содержащая формулу, и куда именно. То есть можно посмотреть, как эта электронная таблица выглядела в 2010 году до того, как она была изменена!
Авторы расследования приводят конкретный пример, как можно использовать calcChain: например, при перемещении формулы из ячейки С7 на место С12 информация об этом сохранится.

И вот что видно, когда смотришь calcChain по исследованию Джино:
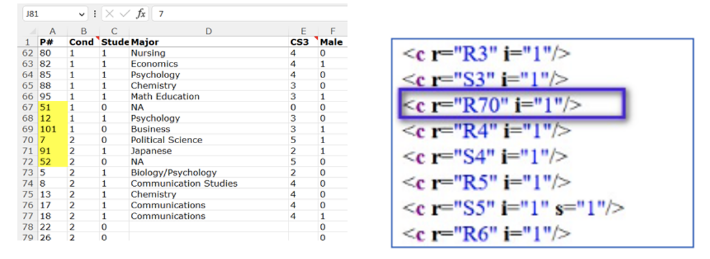
Строка №70 раньше была между рядами 3 и 4, а строки 3 и 4, очевидно, находятся в верхней части электронной таблицы. И, поскольку электронная таблица отсортирована по столбцу B, эти строки относятся к контрольному условию 0, а совсем не 1 и 2, где они в итоге оказались.

Кроме того строки 3 и 4 имеют ID участников №3 и №10. Напомню, что строка 70 имеет ID №7, поэтому до того, как ее переместили вручную, она находилась точно в ожидаемой позиции (между 3 и 10), если 1) это наблюдение изначально было в состоянии 0, и 2) электронная таблица была отсортирована по условию и идентификатору, как есть. Все это убедительно свидетельствует о том, что строка 70 была перемещена из контрольного условия (условие 0) в условие подписи снизу (условие 2).
Вот такая совершенно топорная фальсификация данных.
Мой комментарий
Я работаю в науке, и от себя добавлю, что, к сожалению, «чистота» исследований во многом зависит от добросовестности самого ученого и его научной группы. Иногда ошибки делаются по невнимательности или незнанию правил сбора данных и/или статистической обработки. А иногда – как в этом случае – намеренно, ради красивого эффекта.
Проверить данные тоже возможно далеко не всегда из-за того, что часто их вовсе не публикуют или обещают прислать по запросу (на который потом часто никто не отвечает). Ну и разобраться в чужом огромном датасете, не зная, как он устроен и насколько аккуратно собирался – задача сложная.
Грустно, что в науке, по сути, нет «академической полиции», которая бы как-то наказывала за такие проступки. Максимум – это увольнение/непродление контракта, после чего такие ученые просто идут работать в другие университеты, которым не так важна репутация сотрудников. В случае Джино сейчас – это «administrative leave» – отстранение от работы с сохранением зарплаты и прочих плюшек.
P.S. Если тема интересна, могу сделать посты по второй и третьей частям расследования, а также с нетерпением ждем четвертую!

